고정 헤더 영역
상세 컨텐츠
본문
반응형
비지도 학습
군집화 (Clustering)
비슷한 것들을 그룹화 하는 것
얼핏보면 분류와 비슷하지만 이렇게 다름

비슷한 것들끼리 그룹을 만드는 것 = 군집화
각각을 적당한 위치에 배치시키는 것 = 분류
연관규칙학습 (Association rule learning)
일명 장바구니 학습
⇒ 장바구니에 담긴 상품을 바탕으로 연관 있는 상품을 추천해주는 것과 비슷함
그런 상품이 수천개가 된다고 했을 때 제품들 간의 관계를 파악하는 것을 무척 어려울 것.
이 때 머신러닝이 유용하게 쓰일 수 있음

예를 들어, 위 경우엔 라면을 구매하는 소비자는 계란도 살 가능성이 높다는 상관관계를 파악하고 추천에 이용할 수 있음.
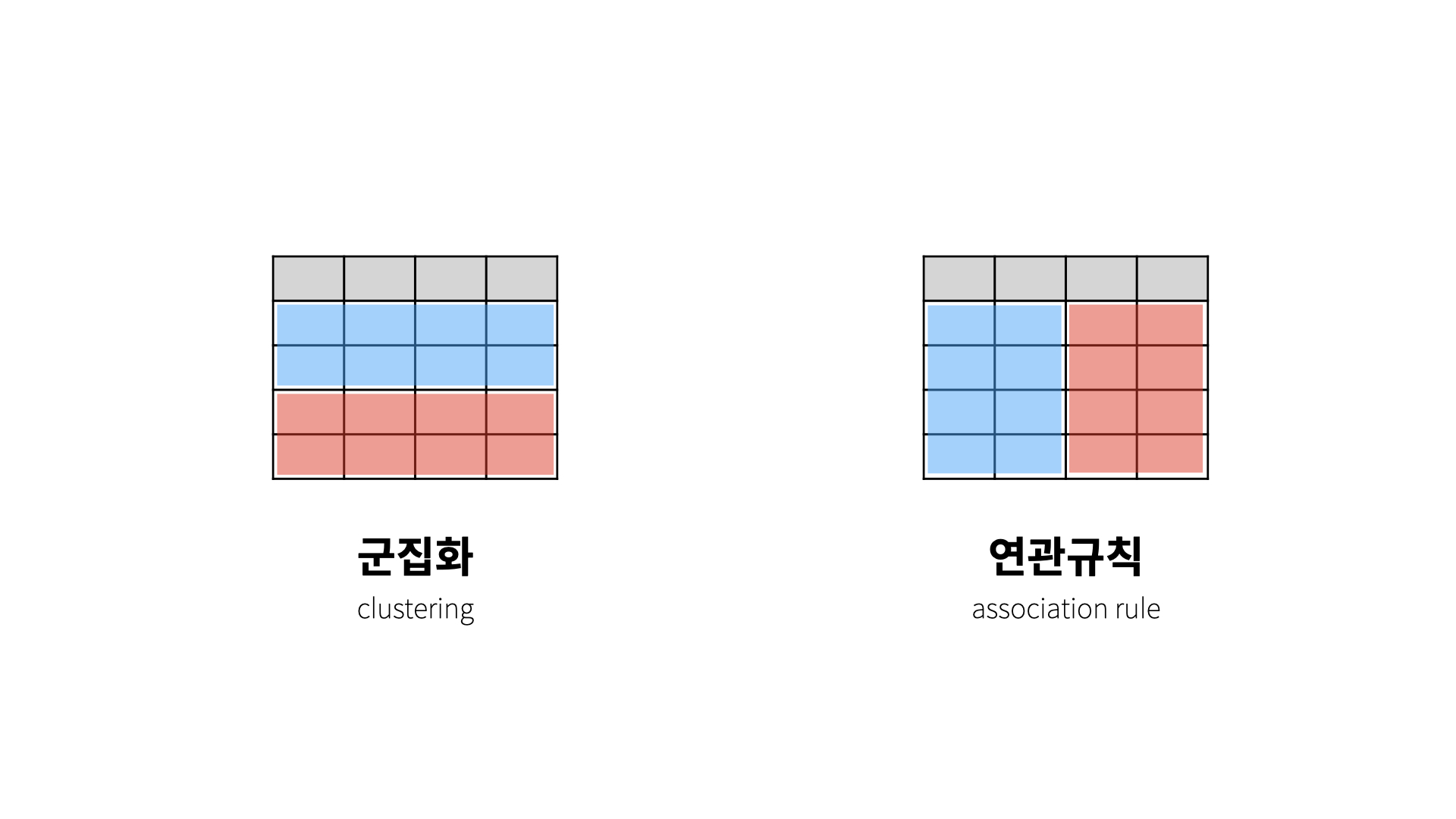
관측치(행)을 그룹화 하는 것 = 군집화
특성(열)을 그룹화 하는 것 = 연관 규칙
비지도 학습 정리
비지도 학습에서 독립변수와 종속변수를 구분하는 것은 중요하지 않음. 탐험적.
지도학습은 과거의데이터를 바탕으로 독립변수와 종속변수의 관계에서 문제를 해결하기 때문에 역사적인 특성을 지님.
강화학습 (Reinforcement Learning)
💡 강화학습의 IDEA :
일단 해보면서 경험을 쌓아가는 것. 결과에 따라 상/벌을 주면서 판단을 강화함.

상/벌이 판단력을 강화하고 이는 행동의 변화로 이어짐.
위 상황에서 각 요소들은 다음에 대응한다.
- 게임 = 환경 (environment)
- 게이머 = 에이전트 (agent)
- 게임화면 = 상태 (state)
- 게이머의 조작 = 행동 (action)
- 상과 벌 = 보상(reward)
- 게이머의 판단력 = 정책(policy)
알파고도 강화학습을 통해 구현된 소프트웨어임. 자율주행에도 강화학습이 이용됨.
△ 팩맨의 게임능력을 향상시킨 예
앞에 저 몬스터들이 있다는 건 어떻게 파악하는 건지 궁금하다 게임상 좌표 정보를 불러오나
△ 멀티 에이전트 숨바꼭질
△ 자동차의 주차능력 향상
주차장에 가까워지면 상을 물체에 부딪히면 벌을 주는 단순한 원리로 기계도 학습이 된다는 게 신기하다
반응형
'IT > 스터디' 카테고리의 다른 글
| 머신러닝야학 7일차 : Tensorflow.js 알아보기 (0) | 2021.01.11 |
|---|---|
| 머신러닝야학 2기 6일차 : 머신러닝 1 완강! (0) | 2021.01.09 |
| 머신러닝야학 2기 4일차 : 머신러닝의 종류, 지도학습 (회귀vs분류) (0) | 2021.01.07 |
| 머신러닝야학 2기 3일차 : 표, 독립변수와 종속변수 (0) | 2021.01.06 |
| 머신러닝야학 2기 2일차 : 머신러닝머신 / 1일차 모델 응용 해보기 (0) | 2021.01.05 |





댓글 영역