고정 헤더 영역
상세 컨텐츠
본문
반응형
준비한 재료
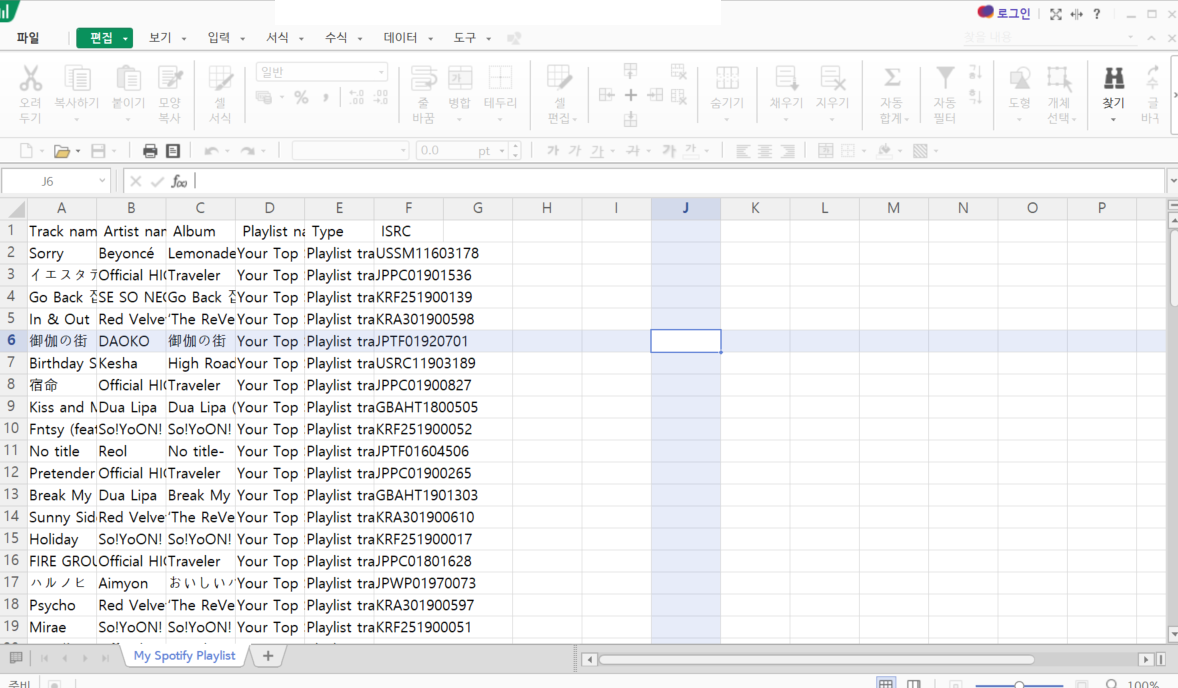
이전 포스팅에서 추출한 플레이리스트로 워드 클라우드를 만들겁니다.
음악 플레이리스트 텍스트, csv 파일로 추출하기 TuneMyMusic
음악 서비스에서 플레이리스트를 텍스트나 csv 파일로 뽑아낼 수 있는 사이트 Tune My Music을 소개합니다. 이런 게 있을 것 같아서 검색해보니 역시나 잘 만든 서비스가 존재했습니다. https://www.tunem
2srin.tistory.com
스포티파이에서 제가 2020년 한해 동안 자주 들은 음악 100개를 선정해준 건데,
어떤 가수의 노래를 많이 들었는지 시각화 하고 싶더라고요.
순전히 호기심에서 출발해서 주먹구구식으로 완성해나가기 때문에 좀 엉성할 수 있습니다.
하지만 저처럼 R을 아직 잘 다루지 못하는 사람한테는 유용할지도 .. 그리고 이미 단어로 구성된 데이터 셋을 얻어왔기 때문에 문장에서 단어를 추출하는 전처리 과정에 대해서는 글 아래의 Reference를 참고하는 편이 나을겁니다.
실행 코드
🌊필요한 패키지들
- wordcloud : 워드 클라우드 만드는 거
- RColorBrewer : 워드 클라우드에 색상 적용
- extrafont : 원하는 폰트 적용
🌊 폰트 세팅
- font_import() : 저는 이거 불러오는데 시간 엄청 걸리더라고요; 콘솔에서 fonts() 입력하면 폰트 리스트 볼 수 있습니다. 폰트는 나중에 함수 안에서 family 속성으로 적용합니다.
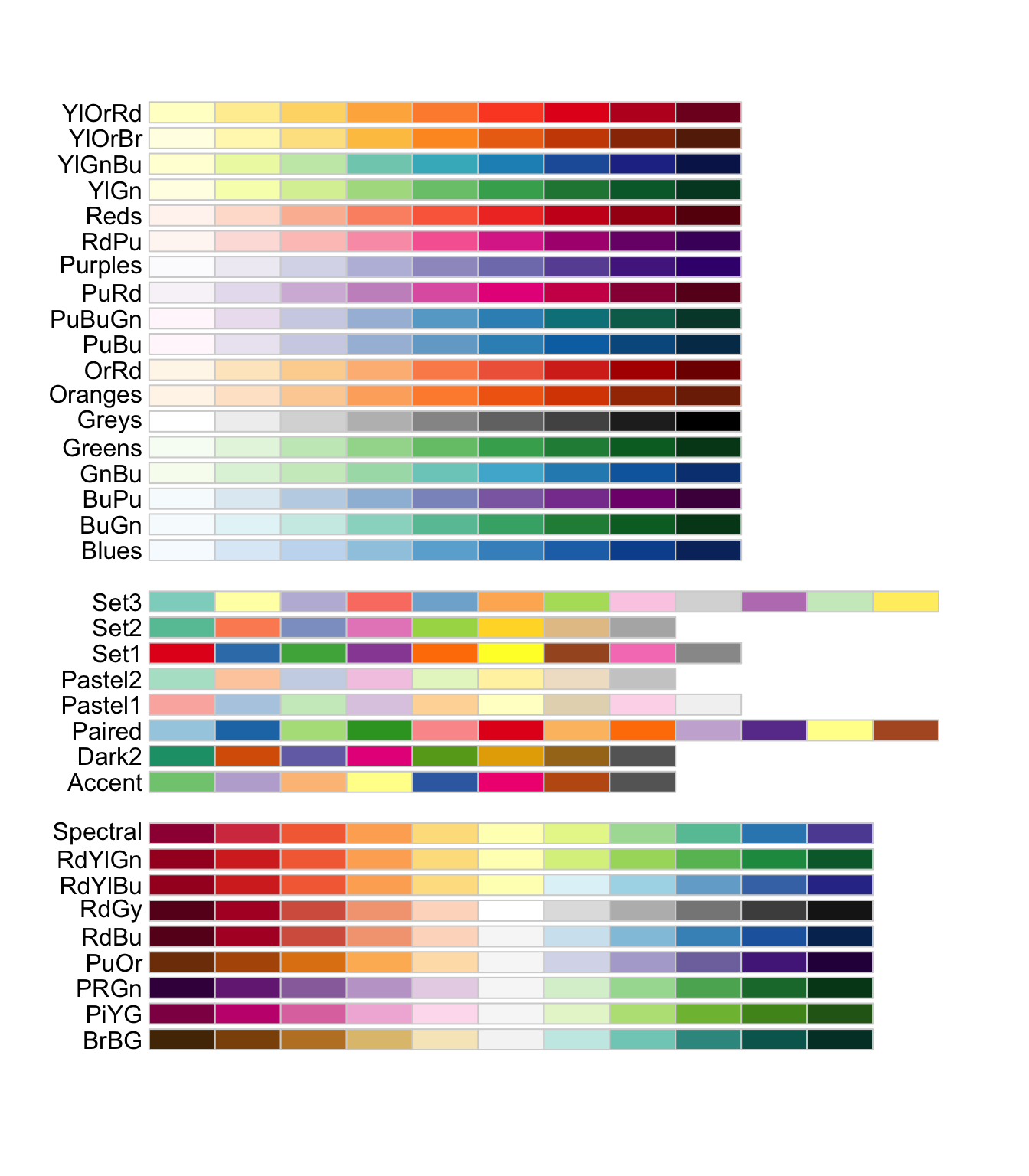
🌊 색상 적용
- brewer.pal(적용할 색상수, "팔레트 이름")
팔레트 종류는 여기 아래에서 고르면 됩니다.
🌊 워드 클라우드 만들기
- par(bg="black") : 흰 배경에선 밝은 글씨가 잘 안보여서 배경을 검은색으로 설정했습니다.
- c(3.5, 0.25) : 글자가 자꾸 잘려서 scale 설정을 이렇게 하라는 조언을 보고 적용함
- max.words : 최대 단어 수
- min.freq : 최소 빈도 수. 예를 들어 빈도수가 1인 건 거르고 싶다 하면 2나 3부터 해도 됩니다. 저는 단어 수가 적어서 그냥 1부터 했습니다.
결과 및 오류들..

글자 잘리는 오류 때문에 몇번이고 재시도 하다가
그럭저럭 마음에 들게 완성했습니다.
R 기초 수업때 이런 걸 할 수 있다고 얘기만 들었고 직접 해보는 건 처음이네요.
#install.packages("devtools")
#library(devtools)
#devtools::install_github("lchiffon/wordcloud2")
#library(wordcloud2)
이거는 wordcloud2 패키지 설치하는 법인데 저는 계속 에러가 뜨더라고요;
그래서 하는 수 없이 그냥 wordcloud로 만들었다는 이야기..
📚 Reference
반응형
'IT > R' 카테고리의 다른 글
| R 일본어 깨짐 문제 인코딩 설정 방법 (0) | 2020.12.09 |
|---|---|
| R airquality 데이터에서 NA값을 제거할 때 주의점 (0) | 2020.08.20 |





댓글 영역